Tinhte FactXem tất cả
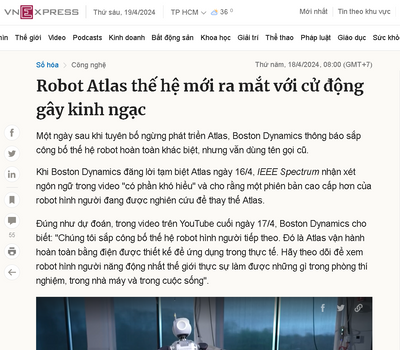
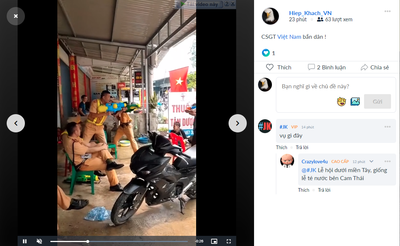


 Hello cả nhà
Hello cả nhà










Microsoft giới thiệu model AI VASA-1: tạo video chân dung người nói chỉ bằng 1 hình tĩnh + voice
Từ một tấm hình chân dung + một đoạn ghi âm giọng nói, model VASA-1 của nhóm nghiên cứu Microsoft châu Á có thể tạo ra một đoạn video lip sync với đầy đủ biểu cảm gương mặt, góc mặt, chuyển động đầu, mắt, miệng, các cơ trên mặt,... Tất cả đều được AI tạo ra real time. Theo nhóm nghiên cứu, VASA là một framework không chỉ có khả năng tạo ra chuyển động của môi, miệng một cách đồng bộ với âm thanh mà nó còn tạo ra nhiều biến đổi khác trên gương mặt để cố "giống thật" nhất. Họ cho biết gen model đã xử lý toàn bộ các biến đổi trên gương mặt và…










Bài nổi bật



















- Audio Tinhte

- Có vẻ như cassette đang thực sự quay lại như một định dạng âm nhạc được giới trẻ yêu thích.
- KEF LSXII LT: Loa Active đa nhiệm, nhỏ gọn, âm thanh ấn tượng và không có ngõ input analog, giá 28tr
- Topping giới thiệu DAC D90III dùng chip giải mã Sabre ES9039SPRO x2, $899
- Trải nghiệm tai nghe fullsize chuyên cho dân làm âm thanh: Sennheiser HD 490 Pro







...đang tải ...










![[Liên tục cập nhật] Tổng hợp thủ thuật One UI 6.1](https://imgproxy7.tinhte.vn/q5Qa5c4FQo-z_fZblJwdI-m_lFNvHWFklZmdBKUk-JM/h:216/plain/https://photo2.tinhte.vn/data/attachment-files/2024/04/8299715_cover-Thu-Thuat-One-UI-6.1-tinhtejpg.jpg)
- Chịu trách nhiệm nội dung: Trần Mạnh Hiệp
- © 2024 Công ty Cổ phần MXH Tinh Tế
- Địa chỉ: Số 70 Bà Huyện Thanh Quan, P. Võ Thị Sáu, Quận 3, TPHCM
- Số điện thoại: 02822460095
- MST: 0313255119
- Giấy phép thiết lập MXH số 11/GP-BTTTT, Ký ngày: 08/01/2019